



Ruby on Rails Tutorial
Изучение Rails на Примерах
Майкл Хартл
Содержание
- Предисловие к русскому изданию
- Глава 1 От нуля к развертыванию
- Глава 2 demo app
- Глава 3 В основном статические страницы
- Глава 4 Rails-приправленный Ruby
- Глава 5 Заполнение шаблона
- Глава 6 Моделирование пользователей
- Chapter 7 Регистрация
- Глава 8 Войти, выйти
- Глава 9 Обновление, демонстрация и удаление пользователей
- Глава 10 Микросообщения пользователей
- Глава 11 Слежение за сообщениями пользователей
Предисловие
Моя компания (CD Baby) была одной из первых громко перешедших на Ruby on Rails, а затем еще громче вернувшейся обратно на PHP (Google расскажет вам об этой драме). Эту книгу, написанную Майклом Хартлом так высоко рекомендовали, что я должен был попробовать её, и Ruby on Rails Tutorial это всё, что я использовал, чтобы вернуться к Rails.
Хотя я уже прошел через много книг по Rails, это одна из немногих, что, наконец, зацепила меня. Было много написано книг типа «Путь Rails» — после которых я чувствовал себя неестественно, но после этой книги я наконец почувствовал себя естественно. Это также единственная книга по Rails, которая соблюдает методику «разработка через тестирование» на всем своем протяжении, этот подход строго рекомендуется специалистами, но он никогда не был так чётко продемонстрирован ранее. Наконец, Git, GitHub и Heroku присутствуют в демо-примерах, автор действительно дает вам почувствовать, что он хотел сделать реальный проект. Учебный код примеров не изолирован.
Линейное повествование — отличный формат. Лично я прошел Rails Tutorial в течении трёх долгих дней, делая все примеры и задачи в конце каждой главы. Делайте всё от начала до конца, не прыгая, и вы получите максимальную пользу.
Наслаждайтесь!
Derek Sivers (sivers.org)
Основатель CD Baby
Благодарности
Ruby On Rails Учебник во многом обязан моей предыдущей книге по Rails, RailsSpace и, следовательно, моему соавтору Aurelius Prochazka. Я хотел бы поблагодарить Aure как за работу, которую он проделал над прошлой книгой, так и за поддержку этой. Я также хотел бы поблагодарить Debra Williams Cauley, редактора обеих книг RailsSpace и Rails Tutorial; до тех пор, пока она не прекратит брать меня на бейсбол, я буду продолжать писать книги для нее.
Я хотел бы поблагодарить огромное количество Рубистов учивших и вдохновлявших меня на протяжении многих лет: David Heinemeier Hansson, Yehuda Katz, Carl Lerche, Jeremy Kemper, Xavier Noria, Ryan Bates, Geoffrey Grosenbach, Peter Cooper, Matt Aimonetti, Gregg Pollack, Wayne E. Seguin, Amy Hoy, Dave Chelimsky, Pat Maddox, Tom Preston-Werner, Chris Wanstrath, Chad Fowler, Josh Susser, Obie Fernandez, Ian McFarland, Steven Bristol, Pratik Naik, Sarah Mei, Sarah Allen, Wolfram Arnold, Alex Chaffee, Giles Bowkett, Evan Dorn, Long Nguyen, James Lindenbaum, Adam Wiggins, Tikhon Bernstam, Ron Evans, Wyatt Greene, Miles Forrest, хороших людей из Pivotal Labs, команду Heroku, thoughtbot ребят, и команду GitHub. Наконец, многих, многих читателей - слишком много чтобы перечислять их здесь - внёсших большое количество предложений по улучшению и сообщивших об ошибках во время написания этой книги, и я с благодарностью признаю их помощь в написании ее настолько хорошей, насколько это было возможно.
Майкл Хартл – автор Ruby on Rails Tutorial, лидирующего введения в веб разработку на Ruby on Rails. Его предыдущий опыт включает в себя написание и разработку RailsSpace - чрезвычайно устаревшего учебника по Rails и разработку Insoshi - некогда популярной, а ныне устаревшей платформы для социальных сетей написанной на Ruby on Rails. В 2011, Майкл получил Ruby Hero Award за его вклад в Ruby сообщество. Он закончил Harvard College, имеет степень Кандидата Физических Наук присвоенную в Caltech и является выпускником предпринимательских курсов Y Combinator.
Копирайт и лицензия
Ruby on Rails Tutorial: Learn Web Development with Rails. Copyright © 2012 by Michael Hartl. Весь исходный код в Ruby on Rails Tutorial доступен под MIT License и Beerware License.
Лицензия MIT
Copyright (c) 2013 Michael Hartl
Данная лицензия разрешает лицам, получившим копию данного программного
обеспечения и сопутствующей документации (в дальнейшем именуемыми
«Программное Обеспечение»), безвозмездно использовать Программное
Обеспечение без ограничений, включая неограниченное право на использование,
копирование, изменение, добавление, публикацию, распространение,
сублицензирование и/или продажу копий Программного Обеспечения, также
как и лицам, которым предоставляется данное Программное Обеспечение,
при соблюдении следующих условий:
Указанное выше уведомление об авторском праве и данные условия должны быть
включены во все копии или значимые части данного Программного Обеспечения.
ДАННОЕ ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ ПРЕДОСТАВЛЯЕТСЯ «КАК ЕСТЬ», БЕЗ КАКИХ-ЛИБО
ГАРАНТИЙ, ЯВНО ВЫРАЖЕННЫХ ИЛИ ПОДРАЗУМЕВАЕМЫХ, ВКЛЮЧАЯ, НО НЕ ОГРАНИЧИВАЯСЬ
ГАРАНТИЯМИ ТОВАРНОЙ ПРИГОДНОСТИ, СООТВЕТСТВИЯ ПО ЕГО КОНКРЕТНОМУ НАЗНАЧЕНИЮ И
ОТСУТСТВИЯ НАРУШЕНИЙ ПРАВ. НИ В КАКОМ СЛУЧАЕ АВТОРЫ ИЛИ ПРАВООБЛАДАТЕЛИ НЕ
НЕСУТ ОТВЕТСТВЕННОСТИ ПО ИСКАМ О ВОЗМЕЩЕНИИ УЩЕРБА, УБЫТКОВ ИЛИ ДРУГИХ
ТРЕБОВАНИЙ ПО ДЕЙСТВУЮЩИМ КОНТРАКТАМ, ДЕЛИКТАМ ИЛИ ИНОМУ, ВОЗНИКШИМ ИЗ,
ИМЕЮЩИМ ПРИЧИНОЙ ИЛИ СВЯЗАННЫМ С ПРОГРАММНЫМ ОБЕСПЕЧЕНИЕМ ИЛИ ИСПОЛЬЗОВАНИЕМ
ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ ИЛИ ИНЫМИ ДЕЙСТВИЯМИ С ПРОГРАММНЫМ ОБЕСПЕЧЕНИЕМ.
/*
* ----------------------------------------------------------------------------
* "ПИВНАЯ ЛИЦЕНЗИЯ" (Ревизия 42):
* Весь код написан Майклом Хартлом. До тех пор пока вы осознаете это,
* вы можете делать с ним все что захотите. Если мы когда нибудь
* встретимся, и если это того стоило, вы можете купить мне
* пиво в ответ.
* ----------------------------------------------------------------------------
*/
Глава 6 Моделирование пользователей
Главу 5 мы закончили созданием страницы-заглушки для регистрации пользователей (Раздел 5.4); в течение следующих четырех глав мы выполним обещание, неявное в этой начинающейся странице регистрации. Первый важный шаг это создание модели данных для пользователей нашего сайта, вместе со способом хранить эти данные. В Главе 7 мы дадим пользователям возможность регистрироваться на нашем сайте и создадим страницу профиля пользователя. Как только пример приложения сможет создавать новых пользователей, мы также позволим им входить и выходить (Глава 8) и в Главе 9 (Раздел 9.2.1) мы узнаем как защитить страницы от несанкцонированного доступа. Взятые вместе, материалы с Главы 6 по Главу 9 разрабатывают полную Rails систему входа и аутентификации. Как вы, возможно, знаете, для Rails существует множество готовых решений для аутентификации; Блок 6.1 поясняет почему разворачивание собственной системы является лучшей идеей.
Это длинная и насыщенная действиями глава и вам она может показаться необычайно сложной, особенно если вы новичок в моделировании данных. Тем не менее, по ее окончании мы создадим весьма качественную систему для валидации, хранения и извлечения информации о пользователе.
Как обычно, если вы пользуетесь Git для контроля версий, сейчас самое время сделать новую ветку для моделирования пользователей:
$ git checkout master
$ git checkout -b modeling-users
(Первая строка здесь только для того чтобы удостовериться, что вы находитесь на master ветке, чтобы тема ветки modeling-users была основана на master ветке. Можно пропустить эту команду, если вы уже находитесь в master ветке.)
6.1 Модель User
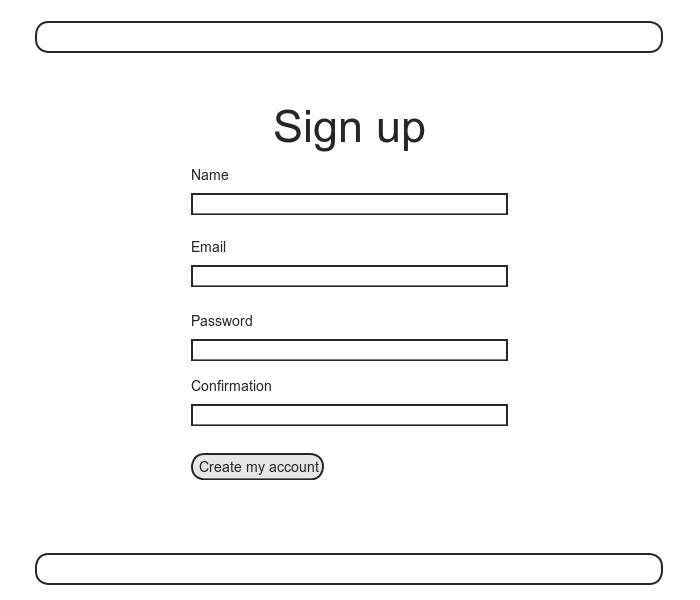
Хотя конечная цель следующих трех глав это создание страницы регистрации для нашего сайта (ее набросок показан на Рис. 6.1), в принятии регистрационной информации сейчас хорошего мало, так как нам в настоящий момент попросту негде ее хранить. Таким образом, первый шаг в регистрации пользователей должен создать структуру данных для получения и хранения их информации.
{kind=link}
В Rails дефолтную структуру данных для модели данных называют, что достаточно естественно, модель (М. в MVC из Раздела 1.2.6). Дефолтное решение Rails для проблемы персистентности состоит в том, чтобы использовать базу данных для долгосрочного хранения данных и дефолтную библиотеку Active Record для взаимодействия с базой данных.1 Active Record идет с массой методов для создания, хранения и поиска объектов данных, и все они не требуют использования языка структурированных запросов (SQL)2 применяемого реляционными базами данных. Кроме того, у Rails есть функции, называемые миграциями, которые позволяют писать определения данных на чистом Ruby, без необходимости изучать язык определения данных (DDL). Как результат, Rails почти полностью изолирует вас от деталей хранения данных. В этой книге, благодаря использованию SQLite для разработки и PostgreSQL (через Heroku) для развертывания (Раздел 1.4), мы проработали эту тему еще дальше, до точки, где нам едва ли когда-нибудь придется задумываться о том, как Rails хранит данные, даже для рабочих приложений.
6.1.1 Миграции базы данных
Можно вспомнить из Раздела 4.4.5 , что мы уже встречали, в созданном нами классе User объекты user с атрибутами name и email. Тот класс служил полезным примером, но он испытывал недостаток в критическом свойстве персистентности: когда мы создали объект User в консоли Rails, он исчез, как только мы вышли. Наша цель в этом Разделе состоит в том, чтобы создать модель для пользователей, которые не будут исчезать так легко.
Как и с классом User в Разделе 4.4.5, мы начнем с моделирования пользователя с двумя атрибутами: name и email, последний мы будем использовать в качестве уникального имени пользователя.3 (Мы добавим атрибут пароля в Разделе 6.3.) В Листинге 4.9 мы сделали это с помощью Ruby-метода attr_accessor:
class User
attr_accessor :name, :email
.
.
.
end
Напротив, при использовании Rails, для моделирования пользователей мы не должны идентифицировать атрибуты явно. Как было кратко отмечено выше, для хранения данных Rails по умолчанию использует реляционные базы данных, которые состоят из таблиц составленных из строк, данных, где у каждой строки есть столбцы атрибутов данных. Например, для того, чтобы сохранить пользователей с именами и адресами электронной почты, мы составим таблицу users со столбцами name и email (с каждой строкой, соответствующей одному пользователю). Называя столбцы таким образом, мы позволяем Active Record выводить атрибуты объектов User для нас.
Давайте посмотрим как это работает. (Если это обсуждение становится слишком абстрактным на ваш взгляд, будьте терпеливы; консольные примеры, начинающиеся в Разделе 6.1.3 и скриншоты браузера базы данных на Рис. 6.3 и Рис. 6.6 должны многое прояснить.) Вспомните из Листинга 5.31 что мы создавали контроллер Users (наряду с new действием) используя команду
$ rails generate controller Users new --no-test-framework
Есть аналогичная команда для создания модели: generate model. Листинг 6.1 показывает команду для генерации модели User с двумя атрибутами, name и email.
$ rails generate model User name:string email:string
invoke active_record
create db/migrate/[timestamp]_create_users.rb
create app/models/user.rb
invoke rspec
create spec/models/user_spec.rb
(Обратите внимание, что, в отличие от множественного соглашения для имен контроллеров, названия моделей - в ед. числе: контроллер Users, но модель User.) Передавая дополнительные параметры name:string и email:string, мы говорим Rails о двух желаемых атрибутах, наряду с тем, какого типа эти атрибуты должны быть (в данном случае, string). Сравните это с включением имен действий в Листинге 3.4 и Листинге 5.31.
Одним из результатов generate команды в Листинге 6.1 является новый файл, названный migration. Миграции обеспечивают возможность постепенного изменения структуры базы данных, так, чтобы наша модель данных могла адаптироваться к изменяющимся требованиям. В случае модели User, миграция создается автоматически сценарием генерации модели; что создает таблицу users с двумя столбцами, name и email, как это показано в Листинге 6.2. (Мы увидим в Разделе 6.2.5 и еще раз в Разделе 6.3 как создавать миграцию с нуля.)
users). db/migrate/[timestamp]_create_users.rb
class CreateUsers < ActiveRecord::Migration
def change
create_table :users do |t|
t.string :name
t.string :email
t.timestamps
end
end
end
Обратите внимание: у названия файла миграции есть префикс в виде временнОй отметки основанной на времени генерации миграции. В первые дни миграций, названия файлов имели префиксы в виде увеличивающихся целых чисел, что приводило к конфликтам в командах разработчиков в случаях когда несколько программистов создавали миграции с совпадающими номерами. Использование временнЫх меток позволило комфортно избегать подобных коллизий.
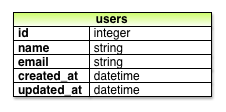
Сама миграция представляет собой метод change определяющий изменения которые необходимо внести в базу данных. В случае Листинга 6.2, change использует Rails метод называемый create_table для создания таблицы в базе данных для хранения пользователей. Метод create_table принимает блок (Раздел 4.3.2) с одной переменной блока, в данном случае названной t (от “table”). Внутри блока метод create_table использует объект t для создания name и email столбцов в базе данных, оба с типом string.4 Здесь название таблицы во множественном числе (users) даже при том, что название модели в ед. числе (User), что отражает лингвистическое соглашение которому следует Rails: модель представляет единственного (отдельного) пользователя, тогда как таблица базы данных состоит из многих пользователей. Заключительная строка в блоке, t.timestamps, является специальной командой, которая создает два волшебных столбца, называемые created_at и updated_at, которые являются временнЫми отметками, которые автоматически записывают, когда данный пользователь создается и обновляется. (Мы увидим конкретные примеры волшебных столбцов в Разделе 6.1.3.) Полная модель данных, представленная этой миграцией, показана на Рис. 6.2.
Мы можем запустить миграцию, известную как “migrating up”, используя rake команду (Блок 2.1) следующим образом:
$ bundle exec rake db:migrate
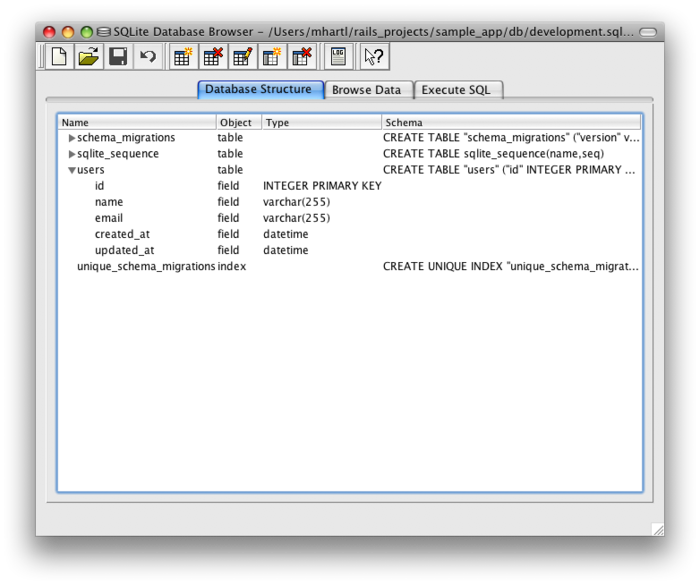
(Можно вспомнить, что мы запускали эту команду прежде, в Разделе 2.2.) При первом запуске db:migrate она создает файл db/development.sqlite3, который является базой данных SQLite5. Мы можем увидеть структуру базы данных, используя превосходный SQLite Database Browser чтобы открыть файл db/development.sqlite3 (Рис. 6.3); сравните со схемой на Рис. 6.2. Вы могли отметить, что есть один столбец в Рис. 6.3 неучтенный в миграции: столбец id. Как было вкратце отмечено в Разделе 2.2, этот столбец создается автоматически, и используется Rails в качестве уникального идентификатора каждой строки.
users таблицей. (полный размер){kind=link}
Большинство миграций являются обратимыми, а это означает что мы можем “migrate down” и переделать ее с помощью единственной Rake задачи, называемой db:rollback:
$ bundle exec rake db:rollback
(См. в Блоке 3.2 еще одну полезную для обращения миграций технику.) Под капотом этой Rake задачи происходит выполнение команды drop_table для удаления таблицы users из базы данных. Причина по которой это работает кроется в том, что метод change знает что drop_table это команда обратная create_table и это означает что способ отката миграции легко определим. В случае необратимых миграций, таких как удаление столбца из базы данных, необходимо определять отдельные up и down методы вместо единственного метода change. Почитайте о миграциях в (rus)Rails Guides дабы составить о них более полное представление.
Если вы откатывали базу данных, migrate up снова перед продолжением:
$ bundle exec rake db:migrate
6.1.2 Файл модели
Мы видели, как генерация модели User в Листинге 6.1 сгенерировала файл миграции (Листинг 6.2) и мы видели на Рис. 6.3 результаты выполнения этой миграции: это обновило файл development.sqlite3, создав таблицу users со столбцами id, name, email, created_at и updated_at. Листинг 6.1 также создал саму модель; остальная часть этого раздела посвящена ее изучению.
Мы начнем с рассмотрения кода для модели User, которая живет в файле user.rb в каталоге app/models/ это, мягко выражаясь, очень компактно (Листинг 6.3).
app/models/user.rbclass User < ActiveRecord::Base
end
Вспомните из Раздела 4.4.2 что синтаксис class User < ActiveRecord::Base означает что класс User наследует от ActiveRecord::Base, таким образом, у модели User автоматически есть вся функциональность ActiveRecord::Base класса. Конечно, знание этого наследования не приносит пользы, если мы не знаем что содержит ActiveRecord::Base так что давайте начнем с конкретных примеров.
6.1.3 Создание объектов user
Как и в Главе 4, наш инструмент - консоль Rails. Так как мы (пока) не хотим производить какие либо изменения в нашей базе данных, мы запустим консоль в sandbox (песочнице):
$ rails console --sandbox
Loading development environment in sandbox
Any modifications you make will be rolled back on exit
>>
Как обозначено полезным сообщением “Любые модификации которые вы сделаете откатятся при выходе”, при работе в песочнице, консоль будет “откатывать” (то есть, отменять) любые изменения базы данных, созданные во время сеанса.
В консольной сессии в Разделе 4.4.5 мы создавали нового пользователя с User.new, к которому мы имели доступ только после подгрузки файла example user из Листинга 4.9. С моделями ситуация иная; как вы можете вспомнить из Раздела 4.4.4, Rails консоль автоматически загружает окружение Rails, которое включает модели. Это означает что мы можем создавать новые объекты user без необходимости подгружать что либо:
>> User.new
=> #<User id: nil, name: nil, email: nil, created_at: nil, updated_at: nil>
Мы видим здесь дефолтное представление объекта user.
Вызванный без параметров, User.new возвращает объект с nil атрибутами. В Разделе 4.4.5 мы спроектировали пример класса User таким образом, чтобы он принимал инициализационный хэш для установки атрибутов объекта; такое решение было обусловлено библиотекой Active Record, которая позволяет инициализировать объекты тем же способом:
>> user = User.new(name: "Michael Hartl", email: "[email protected]")
=> #<User id: nil, name: "Michael Hartl", email: "[email protected]",
created_at: nil, updated_at: nil>
Здесь мы видим, что, как и ожидалось, атрибуты имени и адреса электронной почты были установлены.
Если вы следили за development log, вы, возможно, заметили, что новые строки еще не обнаружились. Это связано с тем, что вызов User.new не касается базы данных; он просто создает новый Ruby объект в памяти. Чтобы сохранить объект user в базе данных, мы вызовем метод save на переменной user:
>> user.save
=> true
Метод save возвращает true если сохранение успешно выполнилось и false если сохранение не выполнено. (Сейчас все сохранения должны успешно выполняться; но в Разделе 6.2 мы увидим случаи, когда некоторые из них не сработают.) После сохранения в логе консоли должна появиться строка с командой SQL INSERT INTO "users". Из-за множества методов, предоставляемых Active Record, в этой книге нам не потребуется необработанный SQL и я буду опускать обсуждение команд SQL с этого момента. Но вы можете многому научиться, читая SQL соответствующий командам Active Record.
Вы, возможно, заметили что у нового объекта user были nil значения для атрибутов id и волшебных столбцов created_at и updated_at. Давайте посмотрим, изменило ли наше save что-нибудь:
>> user
=> #<User id: 1, name: "Michael Hartl", email: "[email protected]",
created_at: "2013-03-11 00:57:46", updated_at: "2013-03-11 00:57:46">
Мы видим что id было присвоено значение 1, в то время как волшебным столбцам были присвоены текущие время и дата.6 В настоящий момент, метки "создан" (created) и "обновлен" (updated) идентичны; мы увидим, что они могут отличаться в Разделе 6.1.5.
Как и с классом User в Разделе 4.4.5, экземпляры модели User предоставляют доступ к своим атрибутам, используя точку:7
>> user.name
=> "Michael Hartl"
>> user.email
=> "[email protected]"
>> user.updated_at
=> Mon, 11 Mar 2013 00:57:46 UTC +00:00
Как мы увидим в Главе 7, часто бывает удобно создать и сохранить модель в два приема, как мы это сделали выше, но Active Record также позволяет вам объединить эти действия в один шаг с User.create:
>> User.create(name: "A Nother", email: "[email protected]")
#<User id: 2, name: "A Nother", email: "[email protected]", created_at:
"2013-03-11 01:05:24", updated_at: "2013-03-11 01:05:24">
>> foo = User.create(name: "Foo", email: "[email protected]")
#<User id: 3, name: "Foo", email: "[email protected]", created_at: "2013-03-11
01:05:42", updated_at: "2013-03-11 01:05:42">
Обратите внимание: User.create, вместо того чтобы возвратить true или false, возвращает сам объект User который мы можем дополнительно присвоить переменной (такой как foo во второй команде выше).
Команда, обратная create это destroy:
>> foo.destroy
=> #<User id: 3, name: "Foo", email: "[email protected]", created_at: "2013-03-11
01:05:42", updated_at: "2013-03-11 01:05:42">
Странно, destroy, как и create, возвращает рассматриваемый объект, хотя я не могу вспомнить что когда-либо использовал значение, возвращаемое destroy. Еще более странно то, что destroyенный объект все еще существует в памяти:
>> foo
=> #<User id: 3, name: "Foo", email: "[email protected]", created_at: "2013-03-11
01:05:42", updated_at: "2013-03-11 01:05:42">
Как мы узнаем, уничтожили ли мы в действительности объект? И как мы можем получить сохраненные и неуничтоженные объекты user из базы данных? Пора узнать, как использовать Active Record, для поиска объектов user.
6.1.4 Поиск объектов user
Active Record предоставляет несколько способов поиска объектов. Давайте используем их, для того, чтобы найти первого пользователя, которого мы создали, и чтобы проверить, что третий пользователь (foo) был уничтожен. Мы начнем с существующего пользователя:
>> User.find(1)
=> #<User id: 1, name: "Michael Hartl", email: "[email protected]",
created_at: "2013-03-11 00:57:46", updated_at: "2013-03-11 00:57:46">
Здесь мы передали id пользователя в User.find; Active Record вернула пользователя с этим атрибутом id.
Давайте посмотрим, существует ли пользователь с id 3 в базе данных:
>> User.find(3)
ActiveRecord::RecordNotFound: Couldn't find User with ID=3
Так как мы уничтожили нашего третьего пользователя в Разделе 6.1.3, Active Record не может найти его в базе данных. Вместо этого find вызывает exception (исключение), которое является способом указать на исключительное событие при выполнении программы, в данном случае, несуществующий Active Record id вызывает исключение ActiveRecord::RecordNotFound.8
В дополнение к универсальному find, Active Record также позволяет нам искать пользователей по определенным атрибутами:
>> User.find_by_email("[email protected]")
=> #<User id: 1, name: "Michael Hartl", email: "[email protected]",
created_at: "2013-03-11 00:57:46", updated_at: "2013-03-11 00:57:46">
Метод find_by_email автоматически создается библиотекой Active Record на основе email атрибута в таблице users. (Как вы догадываетесь, Active Record также создает метод find_by_name.) Начиная с Rails 4.0, более претпочтительным способом для поиска атрибута является использование метода find_by с атрибутом передаваемым в виде хэша:
>> User.find_by(email: "[email protected]")
=> #<User id: 1, name: "Michael Hartl", email: "[email protected]",
created_at: "2013-03-11 00:57:46", updated_at: "2013-03-11 00:57:46">
Поскольку мы будем использовать адреса электронной почты в качестве имен пользователей, этот вид find будет полезен когда мы узнаем как позволить пользователям регистрироваться на нашем сайте (Глава 7). Если вы беспокоитесь об эффективности find_by при большом количестве пользователей - ваше беспокойство вполне обоснованно, но вы немного забегаете вперед; мы обсудим эту проблему и ее решение в Разделе 6.2.5.
Мы закончим несколькими более общими способами поиска пользователей. Во-первых, first:
>> User.first
=> #<User id: 1, name: "Michael Hartl", email: "[email protected]",
created_at: "2013-03-11 00:57:46", updated_at: "2013-03-11 00:57:46">
Естественно, first просто возвращает первого пользователя в базе данных. Есть также all:
>> User.all
=> [#<User id: 1, name: "Michael Hartl", email: "[email protected]",
created_at: "2013-03-11 00:57:46", updated_at: "2013-03-11 00:57:46">,
#<User id: 2, name: "A Nother", email: "[email protected]", created_at:
"2013-03-11 01:05:24", updated_at: "2013-03-11 01:05:24">]
Не сюрприз, что all возвращает массив (Раздел 4.3.1) всех пользователей в базе данных.
6.1.5 Обновление объектов user
После создания объектов мы зачастую хотим их обновить. Есть два основных способа сделать это. Во-первых, мы можем присвоить атрибуты индивидуально, как мы это делали в Разделе 4.4.5:
>> user # Just a reminder about our user's attributes
=> #<User id: 1, name: "Michael Hartl", email: "[email protected]",
created_at: "2013-03-11 00:57:46", updated_at: "2013-03-11 00:57:46">
>> user.email = "[email protected]"
=> "[email protected]"
>> user.save
=> true
Обратите внимание: заключительный шаг необходим, для того чтобы записать изменения в базу данных. Мы можем увидеть, что произойдет без сохранения, используя reload, которая перезагружает объекты, опираясь на информацию в базе данных:
>> user.email
=> "[email protected]"
>> user.email = "[email protected]"
=> "[email protected]"
>> user.reload.email
=> "[email protected]"
Теперь, когда мы обновили пользователя, выполнив user.save, волшебные столбцы отличаются, как и обещалось в Разделе 6.1.3:
>> user.created_at
=> "2013-03-11 00:57:46"
>> user.updated_at
=> "2013-03-11 01:37:32"
Второй основной способ обновления атрибутов заключается в использовании update_attributes:
>> user.update_attributes(name: "The Dude", email: "[email protected]")
=> true
>> user.name
=> "The Dude"
>> user.email
=> "[email protected]"
Update_attributes метод принимает хеш атрибутов и в случае успеха выполняет и обновление, и сохранение за один шаг (возвращающая true чтобы указать что сохранение произошло). Обратите внимание - если какая-нибудь из валидаций выдаст ошибку, что может случиться если, например, пароль был указан как обязательный для сохранения записи (как это реализовано в Разделе 6.3), вызов update_attributes провалится и обновления записи не произойдет. Если мы хотим обновить только один атрибут, то использование сингулярного update_attribute позволит обойти это ограничение:
>> user.update_attribute(:name, "The Dude")
=> true
>> user.name
=> "The Dude"
6.2 Валидации User
У модели User, которую мы создали в Разделе 6.1 теперь есть рабочие атрибуты name и email, но они абсолютно универсальны: любая строка (включая пустую) в настоящий момент допустима. И все же, имена и адреса электронной почты это нечто более определенное. Например, name не должно быть пробелом, email должен соответствовать определенному формату, характерному для адресов электронной почты. Кроме того, так как мы будем использовать адреса электронной почты в качестве уникальных имен пользователей при регистрации, мы не должны позволять дублироваться адресам электронной почты в базе данных.
Короче говоря, мы не должны позволить name и email быть просто любыми строками; мы должны реализовать определенные ограничения для их значений. Active Record позволяет нам налагать такие ограничения, с помощью validations. В этом разделе мы рассмотрим несколько из наиболее распространенных случаев, применив валидации для наличия, длины, формата и уникальности. В Разделе 6.3.4 мы добавим заключительную общепринятую валидацию - подтверждение. И мы увидим в Разделе 7.3 как валидации дают нам удобные сообщения об ошибках когда пользователи предоставляют данные которые нарушают их.
6.2.1 Начальные тесты для пользователей
Как и все прочие фичи этого примера приложения, мы добавим валидации модели User с помощью разработки через тестирование. Поскольку мы не передали флаг
--no-test-framework
при генерации модели User (в отличие, например, от Листинга 5.31), команда в Листинге 6.1 создала начальные спеки для тестирования пользователей, но в данном случае они практически пусты (Листинг 6.4).
spec/models/user_spec.rb
require 'spec_helper'
describe User do
pending "add some examples to (or delete) #{__FILE__}"
end
Здесь просто используется метод pending для указания на то, что мы должны заполнить спек чем-нибудь полезным. Мы cможем увидеть результат его применения подготовив (пустую) тестовую базу данных и запустив спек модели User:
$ bundle exec rake db:migrate
$ bundle exec rake test:prepare
$ bundle exec rspec spec/models/user_spec.rb
*
Finished in 0.01999 seconds
1 example, 0 failures, 1 pending
Pending:
User add some examples to (or delete)
/Users/mhartl/rails_projects/sample_app/spec/models/user_spec.rb
(Not Yet Implemented)
На большинстве систем, ожидающие спеки отображаются желтыми, для указания на то что они находятся как бы между проходящими (зеленый) и провальными (красный) тестами.
Это наша первая встреча с командой которая создает тестовую базу данных с корректной структурой:
$ bundle exec rake test:prepare
Это просто обеспечивает соответствие между моделью данных базы данных для разработки в db/development.sqlite3 и моделью данных тестовой базы данных в db/test.sqlite3.9 (Незапуск этой Rake задачи после миграции является частым источником недоразумений. К тому же, иногда тестовая база данных выходит из строя и требуется вернуть ее в исходное состояние. Если ваш набор тестов загадочным образом рухнул, попробуйте запустить rake test:prepare - возможно это решит проблему.)
Мы последуем совету дефолтного спека и заполним его небольшим количеством RSpec примеров, как это показано в Листинге 6.5.
:name и :email атрибутов. spec/models/user_spec.rbrequire 'spec_helper'
describe User do
before { @user = User.new(name: "Example User", email: "[email protected]") }
subject { @user }
it { should respond_to(:name) }
it { should respond_to(:email) }
end
Блок before, который мы видели в Листинге 5.30), запускает код внутри блока перед каждым тестом, в данном случае, создавая новую переменную экземпляра @user с помощью User.new и валидного инициализационного хэша. Затем
subject { @user }
делает @user дефолтным cубъектом тестирования, как мы это видели прежде в контексте переменной page в Разделе 5.3.4.
Два теста в Листинге 6.5 тестируют на наличие name и email атрибутов:
it { should respond_to(:name) }
it { should respond_to(:email) }
Сами по себе эти тесты не особенно полезны, так как объект User у которого нет (например) атрибута name бросит исключение в блоке before. Но эти тесты проверяют что конструкции user.name и user.email являются валидными, в то время как блок before лишь тестирует атрибуты когда они передаются в виде хэша методу new. К тому же, тестирование атрибутов модели это полезная конвенция, так как она позволяет нам с первого взгляда увидеть методы на которые должна отвечать модель.
Методы respond_to неявно используют Ruby метод respond_to? который принимает символ и возвращает true в случае если объект отвечает на данный метод или атрибут и возвращает false в противном случае:
$ rails console --sandbox
>> user = User.new
>> user.respond_to?(:name)
=> true
>> user.respond_to?(:foobar)
=> false
(Вспомните из Раздела 4.2.3 что Ruby использует знак вопроса для обозначения таких true/false булевых методов.) Сами тесты опираются на булевую конвенцию используемую RSpec: код
@user.respond_to?(:name)
может быть протестирован с помощью такого RSpec кода
it "should respond to 'name'" do
expect(@user).to respond_to(:name)
end
Благодаря subject { @user }, мы можем написать это в альтернативном однострочном стиле, впервые представленном в Разделе 5.3.4:
it { should respond_to(:name) }
Такой вид тестов позволяет нам использовать TDD для добавления новых атрибутов и методов к нашей модели User и, в качестве побочного эффекта, мы получаем хорошую спецификацию методов на которые должны отвечать все объекты User.
Так как мы уже подготовили тестовую базу данных командой rake test:prepare, тесты должны пройти:
$ bundle exec rspec spec/
6.2.2 Валидация наличия
Возможно самой элементарной валидацией является валидация наличия, которая просто проверяет что данный атрибут имеется в наличии. Например, в данном разделе мы убеждаемся что оба name и email поля заполнены прежде чем пользователь будет сохранен в базе данных. В Разделе 7.3.3 мы увидим как распространить это требование на форму регистрации новых пользователей.
Мы начнем с теста на наличие атрибута name. Хотя первым шагом в TDD является написание провального теста (Раздел 3.2.1), в данном случае мы пока недостаточно знаем о валидации для того чтобы написать годный тест, так что мы вначале напишем валидацию и немного поиграем с ней в консоли, - чтобы побольше узнать о ней. Затем мы закомментируем валидацию, напишем провальный тест и проверим что раскомментирование валидации приводит к прохождению теста. Эта процедура может показаться излишне педантичной для такого простого теста, но я видел много “простых” тестов, которые на самом деле тестировали неправильные вещи; дотошность в TDD это просто единственный способ быть уверенными в том что мы тестируем правильные вещи. (Такая техника закомментирования также полезна при спасении приложения, код которого уже написан, но—quelle horreur! — (# какой ужас - фр.) не имеет тестов.)
Способ валидации наличия атрибута имени заключается в применении метода validates с аргументом presence: true, как это показано в Листинге 6.6. Аргумент presence: true это одноэлементный хэш опций; вспомните из Раздела 4.3.4 что фигурные скобки являются необязательными при передаче хеша в качестве последнего аргумента в методе. (Как отмечено в Разделе 5.1.1, использование хэшэй опций это очень распространенный прием в Rails.)
name атрибута. app/models/user.rbclass User < ActiveRecord::Base
validates :name, presence: true
end
Листинг 6.6 возможно выглядит как магия, но validates это просто метод. Эквивалентная Листингу 6.6 формулировка с применением скобок выглядит следующим образом:
class User < ActiveRecord::Base
validates(:name, presence: true)
end
Давайте заскочим в консоль чтобы увидеть эффект добавления валидации к нашей модели User:10
$ rails console --sandbox
>> user = User.new(name: "", email: "[email protected]")
>> user.save
=> false
>> user.valid?
=> false
Здесь user.save возвращает false, указывая на провальное сохранение. В заключительной команде мы используем valid? метод, который возвращает false когда объект приводит к сбою одной или более валидаций, и true когда все валидации проходят. В данном случае у нас есть только одна валидация, таким образом, мы знаем, какая именно провалилась, но все же не лишним будет в этом убедиться с помощью объекта errors, генерируемого при отказе:
>> user.errors.full_messages
=> ["Name can't be blank"]
(Сообщение об ошибке - подсказка, говорящая о том что Rails проверяет наличие атрибута, используя blank? метод, который мы видели в конце Раздела 4.4.3.)
Теперь о провальном тесте. Чтобы гарантировать что наш начальный тест перестанет работать, давайте закомментируем валидацию (Листинг 6.7).
app/models/user.rbclass User < ActiveRecord::Base
# validates :name, presence: true
end
Начальный тест валидации представлен в Листинге 6.8.
name. spec/models/user_spec.rbrequire 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "[email protected]")
end
subject { @user }
it { should respond_to(:name) }
it { should respond_to(:email) }
it { should be_valid }
describe "when name is not present" do
before { @user.name = " " }
it { should_not be_valid }
end
end
Первый новый тест это просто проверка на то что объект @user изначально валиден:
it { should be_valid }
Это еще один пример булевой конвенции RSpec которую мы видели ранее в Разделе 6.2.1: в каждом случае, когда объект отвечает на булевый метод foo?, существует соответствующий тестовый метод с именем be_foo. В данном случае мы можем протестировать результат вызова
@user.valid?
с помощью
it "should be valid" do
expect(@user).to be_valid
end
Как и прежде, subject { @user } позволяет нам использовать однострочный стиль, что приводит к
it { should be_valid }
Второй тест вначале назначает пользовательскому имени недопустимое значение, а затем проверяет что получившийся объект @user невалиден:
describe "when name is not present" do
before { @user.name = " " }
it { should_not be_valid }
end
Здесь используется блок before для назначения невалидного значения атрибуту name, а затем происходит проверка того что получившийся объект user невалиден.
Теперь необходимо убедиться в том что в данный момент тесты провальны:
$ bundle exec rspec spec/models/user_spec.rb
...F
4 examples, 1 failure
Теперь раскомментируем валидацию (т.е., вернемся от Листинга 6.7 обратно к Листингу 6.6) для того чтобы получить прохождение теста:
$ bundle exec rspec spec/models/user_spec.rb
....
4 examples, 0 failures
Конечно, мы также хотим валидировать наличие адресов электронной почты. Тест (Листинг 6.9) походит на аналогичный тест для атрибута name.
email. spec/models/user_spec.rb
require 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "[email protected]")
end
.
.
.
describe "when email is not present" do
before { @user.email = " " }
it { should_not be_valid }
end
end
Реализация практически та же, что и в Листинге 6.10.
name и email. app/models/user.rbclass User < ActiveRecord::Base
validates :name, presence: true
validates :email, presence: true
end
Теперь все тесты должны проходить и валидации “наличия” готовы.
6.2.3 Валидация длины
Мы ограничили нашу модель User требованием имени для каждого пользователя, но мы должны пойти еще дальше: имена пользователей будут отображаться на сайте, таким образом, мы должны будем реализовать некоторое ограничение их длины. С работой, проделанной в Разделе 6.2.2, этот шаг легок.
Мы начнем с теста. В выборе максимальной длины нет ничего хитрого; мы просто примем 50 как разумную верхнюю границу, что означает что имена длиной в 51 символ будут слишком длинными (Листинг 6.11).
name. spec/models/user_spec.rb
require 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "[email protected]")
end
.
.
.
describe "when name is too long" do
before { @user.name = "a" * 51 }
it { should_not be_valid }
end
end
Для удобства мы использовали “мультипликацию строки” в Листинге 6.11 для создания строки длиной в 51 символ. Мы можем увидеть как это работает, используя консоль:
>> "a" * 51
=> "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"
>> ("a" * 51).length
=> 51
Тест в Листинге 6.11 должен провалиться. Чтобы заставить его пройти, мы должны знать об аргументе валидации, ограничивающим длину, :length, наряду с :maximum параметром реализуют верхнюю границу (Листинг 6.12).
name атрибута. app/models/user.rbclass User < ActiveRecord::Base
validates :name, presence: true, length: { maximum: 50 }
validates :email, presence: true
end
С нашим комплектом тестов, вновь проходящим, мы можем идти дальше, к более интересной валидации: валидации формата электронной почты.
6.2.4 Валидация формата
Наши валидации для атрибута name реализуют только минимальные ограничения: любое непустое имя длиной до 51 символов пройдет; но, конечно, атрибут email должен соответствовать более строгим требованиям. До сих пор мы отклоняли только пустой адрес электронной почты; в этом разделе мы потребуем, чтобы адреса электронной почты соответствовали знакомому образцу [email protected].
Ни тесты, ни валидации не будут исчерпывающими - лишь достаточно хорошими, чтобы принять большую часть допустимых адресов электронной почты и отклонить большинство недопустимых. Мы начнем с пары тестов, включающих наборы допустимых и недопустимых адресов. Чтобы сделать эти наборы, стоит узнать о полезной технике создания массивов строк, как показано в этом консольном сеансе:
>> %w[foo bar baz]
=> ["foo", "bar", "baz"]
>> addresses = %w[[email protected] [email protected] [email protected]]
=> ["[email protected]", "[email protected]", "[email protected]"]
>> addresses.each do |address|
?> puts address
>> end
[email protected]
[email protected]
[email protected]
Здесь мы выполнили итерации по элементам массива addresses используя each метод (Раздел 4.3.2). Вооружившись этой техникой мы готовы написать несколько базовых тестов для валидации формата электронной почты (Листинг 6.13).
spec/models/user_spec.rbrequire 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "[email protected]")
end
.
.
.
describe "when email format is invalid" do
it "should be invalid" do
addresses = %w[user@foo,com user_at_foo.org example.user@foo.
foo@bar_baz.com foo@bar+baz.com]
addresses.each do |invalid_address|
@user.email = invalid_address
expect(@user).not_to be_valid
end
end
end
describe "when email format is valid" do
it "should be valid" do
addresses = %w[[email protected] [email protected] [email protected] [email protected]]
addresses.each do |valid_address|
@user.email = valid_address
expect(@user).to be_valid
end
end
end
end
Как было отмечено выше, они не являются исчерпывающими, но мы проверили обычные допустимые формы электронной почты [email protected], [email protected] (верхний регистр, подчеркивание и соединенные домены) и [email protected] (стандартное корпоративное имя пользователя first.last, с двухбуквенным доменом верхнего уровня jp (Japan)), наряду с несколькими недопустимыми формами.
Код приложения для валидации формата электронной почты использует регулярное выражение (или regex) для определения формата, наряду с :format аргументом для validates метода (Листинг 6.14).
app/models/user.rbclass User < ActiveRecord::Base
validates :name, presence: true, length: { maximum: 50 }
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i
validates :email, presence: true, format: { with: VALID_EMAIL_REGEX }
end
Здесь регулярное выражение VALID_EMAIL_REGEX это константа, которая обозначается в Ruby именем начинающимся с большой буквы. Код
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i
validates :email, presence: true, format: { with: VALID_EMAIL_REGEX }
обеспечивает допустимость адресов электронной почты соответствующих образцу, все остальные будут считаться недопустимыми.
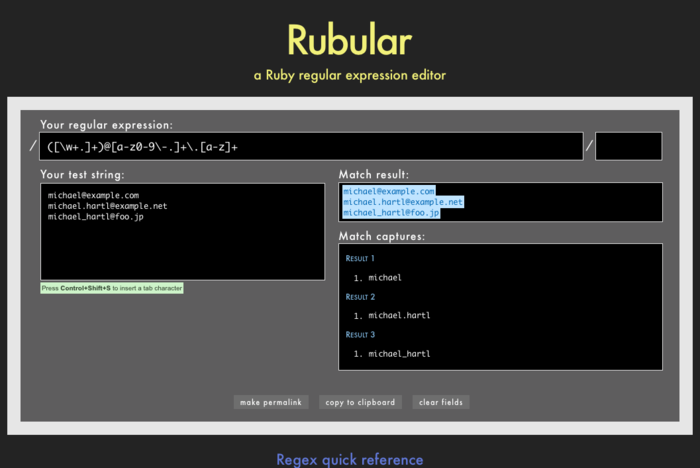
Так, откуда появился образец? Регулярные выражения состоят из краткого (некоторые сказали бы нечитаемого) языка для сравнения текстовых паттернов; изучение построения регулярных выражений это искусство и для начала я разбил VALID_EMAIL_REGEX на небольшие куски (Таблица 6.1).11 Я считаю что замечательный онлайн редактор регулярных выражений Rubular (Рис. 6.4) просто незаменим для изучения регулярных выражений.12 Cайт Rubular имеет красивый интерактивный интерфейс для создания регулярных выражений, а также удобную Regex справку. Я призываю вас изучать Таблицу 6.1 с открытым в браузере Rubular-ом. Никакое чтение о регулярных выражениях не может заменить пару часов игры с Rubular. (Примечание: если вы хотите использовать регулярное выражение из Листинга 6.14 в Rubular, вам следует пропустить символы \A и \z.)
| Выражение | Значение |
|---|---|
| /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i | полное регулярное выражение |
| / | начало регулярного выражения |
| \A | соответствует началу строки |
| [\w+\-.]+ | по крайней мере один символ слова, плюс, дефис или точка |
| @ | буквально “знак собаки” |
| [a-z\d\-.]+ | по крайней мере одна буква, цифра, дефис или точка |
| \. | буквальная точка |
| [a-z]+ | по крайней мере одна буква |
| \z | соответствует концу строки |
| / | конец регулярного выражения |
| i | нечувствительность к регистру |
Кстати, на самом деле существует полное регулярное выражение для сопоставления адресов электронной почты в соответствии с официальным стандартом, но волноваться не стоит. Экземпляр из Листинга 6.14 тоже хорош, возможно даже лучше чем официальный.13 Однако выражение приведенное выше имеет один недостаток: оно позволяет невалидные адреса вроде [email protected] содержащих последовательно расположенные точки. Исправление этого недочета оставлено в качестве упражнения (Раздел 6.5).
{kind=link}
Теперь тесты должны пройти. (Фактически, тесты для валидных адресов электронной почты должны были проходить все время; так как регулярные выражения, как известно, подвержены ошибкам, действительные испытания электронной почты в основном заключаются в санитарной проверке на VALID_EMAIL_REGEX.) Это означает, что осталось рассмотреть только одно ограничение: обеспечение уникальности адресов электронной почты.
6.2.5 Валидация уникальности
Для обеспечения уникальность адресов электронной почты (так, чтобы мы могли использовать их в качестве имен пользователей) мы будем использовать :unique опцию для validates метода. Но предупреждаю: есть важное предостережение, так что не просто просмотрите раздел, а прочитайте его внимательно.
Мы начнем, как обычно, с наших тестов. В наших предыдущих тестах модели мы, главным образом, использовали User.new, который только создает объект Ruby в памяти, но для тестов уникальности мы фактически должны поместить запись в базу данных.14 (Первый) тест дублирования электронной почты представлен в Листинге 6.15.
spec/models/user_spec.rbrequire 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "[email protected]")
end
subject { @user }
.
.
.
describe "when email address is already taken" do
before do
user_with_same_email = @user.dup
user_with_same_email.save
end
it { should_not be_valid }
end
end
Методика заключается в создании пользователя с тем же адресом электронной почты, что и у @user, чего мы достигаем с помощью @user.dup, который создает дубликат пользователя с теми же атрибутами. Поскольку мы затем сохраняем этого пользователя, оригинальный @user будет иметь адрес электронной почты который уже существует в базе данных и, следовательно, он не должен быть валидным.
Мы можем получить прохождение теста из Листинга 6.15 с кодом из Листинга 6.16.
app/models/user.rb
class User < ActiveRecord::Base
.
.
.
validates :email, presence: true, format: { with: VALID_EMAIL_REGEX },
uniqueness: true
end
И все же мы не закончили. Адреса электронной почты не чувствительны к регистру — [email protected] равен [email protected] или [email protected] — и наша валидация должна учитывать и этот случай.15 Мы тестируем на это с помощью кода из Листинга 6.17.
spec/models/user_spec.rbrequire 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "[email protected]")
end
subject { @user }
.
.
.
describe "when email address is already taken" do
before do
user_with_same_email = @user.dup
user_with_same_email.email = @user.email.upcase
user_with_same_email.save
end
it { should_not be_valid }
end
end
Здесь мы используем upcase метод на строках (описан кратко в Разделе 4.3.2). Этот тест делает то же самое что и первый тест на дублирование адресов электронной почты, но с прописным адресом электронной почты. Если этот тест кажется вам немного абстрактным, запустите консоль:
$ rails console --sandbox
>> user = User.create(name: "Example User", email: "[email protected]")
>> user.email.upcase
=> "[email protected]"
>> user_with_same_email = user.dup
>> user_with_same_email.email = user.email.upcase
>> user_with_same_email.valid?
=> true
Конечно, сейчас user_with_same_email.valid? является true, так как это провальный тест, но мы хотим, чтобы оно было false. К счастью, :uniqueness принимает опцию, :case_sensitive, как раз для этой цели (Листинг 6.18).
app/models/user.rb
class User < ActiveRecord::Base
.
.
.
validates :email, presence: true, format: { with: VALID_EMAIL_REGEX },
uniqueness: { case_sensitive: false }
end
Обратите внимание: мы просто заменили true на case_sensitive: false; Rails в этом случае делает вывод, что :uniqueness должно быть true. В этой точке наше приложение обеспечивает уникальность адресов электронной почты и наш набор тестов должен пройти.
Предостережение уникальности
Есть одна небольшая проблема, предостережение, на которое я ссылался выше:
Использование validates :uniqueness не гарантирует уникальности.
D’oh! Но что может может пойти не так? А вот что:
- Алиса регистрируется на сайте, с email адресом [email protected].
- Алиса случайно кликает, “Submit” дважды, отправляя два запроса в быстрой последовательности.
- Затем происходит следующее: первый запрос создает пользователя в памяти, который проходит проверку, второй запрос делает то же самое, первый запрос пользователя сохраняется, второй запрос пользователя сохраняется.
- Результат: две пользовательские записи с одинаковыми адресами электронной почты, несмотря на валидацию уникальности.
Если вышеописанная последовательность кажется вам неправдоподобной, поверьте мне, это не так: это происходит на любом Rails сайте со значительным трафиком. К счастью, решение просто в реализации, нам просто необходимо обеспечить уникальность также на уровне базы данных. Наш метод заключается в создании в базе данных индекса столбца электронной почты и последующем требовании уникальности этого индекса.
Индекс адреса электронной почты представляет собой обновление требований к нашей модели данных что (как обсуждалось в Разделе 6.1.1) делается в Rails посредством миграций. Мы видели в Разделе 6.1.1 что генерация модели User автоматически создает новую миграцию (Листинг 6.2); в данном случае мы добавляем структуру к существующей модели, таким образом, мы должны создать миграцию непосредственно, используя migration генератор:
$ rails generate migration add_index_to_users_email
В отличие от миграции для пользователей, миграция уникальности электронной почты не предопределена, таким образом, мы должны заполнить ее содержание кодом из Листинга 6.19.16
db/migrate/[timestamp]_add_index_to_users_email.rbclass AddIndexToUsersEmail < ActiveRecord::Migration
def change
add_index :users, :email, unique: true
end
end
Здесь используется Rails метод add_index для добавления индекса на столбце email таблицы users. Индекс сам по себе не обеспечивает уникальность, но это делает опция unique: true.
Заключительный шаг должен мигрировать базу данных:
$ bundle exec rake db:migrate
(Если это не сработало, попробуйте закрыть все консольные сессии в песочнице, которая может блокировать базу данных, тем самым препятствуя миграции.) Если вам интересно посмотреть на практический результат выполнения этой команды, посмотрите файл db/schema.rb, который теперь должен содержать строку подобную этой:
add_index "users", ["email"], name: "index_users_on_email", unique: true
К сожалению, есть еще одно изменение которое мы должны сделать для того чтобы быть уверенными в уникальности email адресов - все email адреса должны быть в нижнем регистре, прежде чем они будут сохранены в базе данных. Причина заключается в том что не все адаптеры баз данных используют регистрозависимые индексы.17 Мы можем достигнуть этого с помощью функции обратного вызова, которая является методом, который вызывается в конкретный момент жизни объекта Active Record (см. Rails API). В данном случае мы будем использовать функцию обратного вызова before_save для того чтобы принудить Rails переводить в нижний регистр email атрибут перед сохранением пользователя в базу данных, как это показано в Листинге 6.20.
app/models/user.rbclass User < ActiveRecord::Base
before_save { self.email = email.downcase }
.
.
.
end
Код в Листинге 6.20 передает блок в коллбэк before_save и назначает email адрес пользователя равным его текущему значению в нижнем регистре с помощью метода строки downcase. Этот код довольно продвинутый и в этой точке я советую вам просто поверить в то что он работает; если вы все же сомневаетесь, закомментируйте валидацию уникальности из Листинга 6.16 и попробуйте создать пользователей с идентичными email адресами для того чтобы посмотреть на результирующую ошибку. (Мы вновь увидим эту технику в Разделе 8.2.1, где мы будем использовать конвенцию method reference.) Написание теста для кода в Листинге 6.20 остается в качестве упражнения (Раздел 6.5).
Теперь вышеописанный сценарий с Алисой будет хорошо работать: база данных сохранит запись пользователя, основанную на первом запросе, и отвергнет второе сохранение за нарушение уникальности. (Ошибка появится в логе Rails, но в этом нет ничего плохого. Можно даже отловить ActiveRecord::StatementInvalid исключение, но в этом учебном руководстве мы не будем заморачиваться этим шагом.) Добавление этого индекса на атрибут адреса электронной почты преследует вторую цель, кратко рассмотренную в Разделе 6.1.4: он решает проблему эффективности поиска пользователя с помощью find_by (Блок 6.2).
6.3 Добавление безопасного пароля
В этом разделе мы добавим последний из базовых атрибутов модели User: безопасный пароль используемый для аутентификации пользователей примера приложения. Методика заключается в запросе у каждого пользователя пароля (с подтверждением), а затем сохранении зашифрованной версии пароля в базе данных. Мы также добавим способ аутентификации пользователя опирающийся на данный пароль, метод, который мы будем использовать в Главе 8 для того чтобы дать пользователям возможность входить на сайт.
Метод для аутентификации будет принимать введеный пароль, шифровать его и сравнивать зашифрованное значение с хранящимся в базе данных. Если они совпадают, то введеный пароль корректен и пользователь аутентифицирован. Сравнивая зашифрованные пароли вместо того чтобы сравнивать пароли непосредственно, мы получаем возможность аутентифицировать пользователей не храня в базе данных сами пароли, тем самым избежав серьезной дыры в системе безопасности нашего приложения.
БОльшая часть механики безопасного пароля будет реализовано с помощьо одного Rails-метода называемого has_secure_password (впервые был представлен в Rails 3.1). Поскольку очень многое в дальнейшем зависит от этого единственного метода, трудно разрабатывать безопасные пароли постепенно. Начиная с Раздела 6.3.2 я рекомендую добавить метод has_secure_password зарание, а затем комментировать его перед добавлением каждого нового теста для того чтобы обеспечить правильный цикл TDD. (Поскольку скринкасты позволяют демонстрировать более постепенный подход к разработке, заинтересованным читателям следует посмотреть Ruby on Rails Tutorial screencasts для более полного понимания этого материала.)
6.3.1 Зашифрованный пароль
Мы начнем с необходимого изменения модели данных для пользователей, что подразумевает добавление password_digest столбца в таблицу users (Рис. 6.5). Название digest пришло из терминологии криптографических хэш функций, а само имя password_digest необходимо для работы реализации в Разделе 6.3.4. Как следует зашифровав пароль, мы обеспечим невозможность получения доступа к сайту атакером, даже если он умудрится получить копию базы данных.
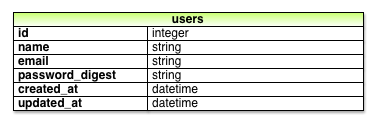
password_digest.Мы будем использовать самую новомодную хэш функцию, называемую bcrypt для необратимого шифрования пароля в виде хэша пароля. Для того чтобы использовать bcrypt в примере приложения нам необходимо добавить гем bcrypt-ruby в наш Gemfile (Листинг 6.21).
bcrypt-ruby в Gemfile.source 'https://rubygems.org'
ruby '2.0.0'
#ruby-gemset=railstutorial_rails_4_0
gem 'rails', '4.0.2'
gem 'bootstrap-sass', '2.3.2.0'
gem 'bcrypt-ruby', '3.1.2'
.
.
.
Затем запускаем bundle install:
$ bundle install
Поскольку мы хотим чтобы пользователи имели столбец password digest, объект user должен отвечать на password_digest, что приводит нас к тесту показанному в Листинге 6.22.
password_digest. spec/models/user_spec.rb
require 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "[email protected]")
end
subject { @user }
it { should respond_to(:name) }
it { should respond_to(:email) }
it { should respond_to(:password_digest) }
.
.
.
end
Для того чтобы получить прохождение этого теста мы вначале генерируем соответствующую миграцию для столбца password_digest:
$ rails generate migration add_password_digest_to_users password_digest:string
Здесь первый аргумент это название миграции и мы также предоставили второй аргумент с названием и типом атрибута который мы хотим создать. (Сравните это с начальной генерацией таблицы users в Листинге 6.1.) Мы можем выбрать любое название для миграции, но было бы удобно, если бы ее название заканчивалось на _to_users, поскольку в этом случае Rails автоматически построит миграцию для добавления столбцов к таблице users. Кроме того, включив второй аргумент, мы дали Rails достаточно информации для построения для нас всей миграции, как это видно в Листинге 6.23.
password_digest к таблице users. db/migrate/[ts]_add_password_digest_to_users.rb
class AddPasswordDigestToUsers < ActiveRecord::Migration
def change
add_column :users, :password_digest, :string
end
end
Этот код использует метод add_column для добавления столбца password_digest к таблице users.
Мы можем получить прохождение провального теста из Листинга 6.22 запустив миграцию базы данных разработки и подготовив тестовую базу данных:
$ bundle exec rake db:migrate
$ bundle exec rake test:prepare
$ bundle exec rspec spec/
6.3.2 Пароль и подтверждение
Как видно на наброске Рис. 6.1, мы ожидаем что пользователи должны будут подтверждать их пароли, что является общепринятой в сети практикой минимизирующей риск опечаток при введении пароля. Мы можем реализовать это на уровне контроллера, но принято делать это в модели и использовать Active Record для наложения этого ограничения. Метод заключается в добавлении password и password_confirmation атрибутов к модели User и последующем требовании совпадения этих двух атрибутов перед сохранением записи в базе данных. В отличие от всех остальных атрибутов, что мы видели до этого, атрибуты пароля будут виртуальными — они будут лишь временно существовать в памяти и не будут постоянно храниться в базе данных. Как мы увидим в Разделе 6.3.4, has_secure_password реализует эти виртуальные атрибуты автоматически .
Мы начнем с respond_to тестов для пароля и его подтверждения, как это показано в Листинге 6.24.
password и password_confirmation. spec/models/user_spec.rbrequire 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "[email protected]",
password: "foobar", password_confirmation: "foobar")
end
subject { @user }
it { should respond_to(:name) }
it { should respond_to(:email) }
it { should respond_to(:password_digest) }
it { should respond_to(:password) }
it { should respond_to(:password_confirmation) }
it { should be_valid }
.
.
.
end
обратите внимание - мы добавили :password и :password_confirmation в хэш инициализации для User.new:
before do
@user = User.new(name: "Example User", email: "[email protected]",
password: "foobar", password_confirmation: "foobar")
end
Мы определенно не хотим чтобы пользователи могли вводить пустые пароли, так что мы добавим еще один тест для валидации наличия пароля:
describe "when password is not present" do
before { @user.password = @user.password_confirmation = " " }
it { should_not be_valid }
end
Поскольку мы будем вскоре тестировать несовпадение пароля, здесь мы будем тестировать существование валидации наличия установив пароль и его подтверждение равными чистой строке.
Мы также хотим убедиться что пароль и его подтверждение совпадают. Случай, когда они совпадают покрыт с помощью it { should be_valid }, так что нам осталось протестировать только случай несовпадения:
describe "when password doesn't match confirmation" do
before { @user.password_confirmation = "mismatch" }
it { should_not be_valid }
end
Собрав все вместе, мы получаем (провальные) тесты в Листинге 6.25.
spec/models/user_spec.rbrequire 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "[email protected]",
password: "foobar", password_confirmation: "foobar")
end
subject { @user }
it { should respond_to(:name) }
it { should respond_to(:email) }
it { should respond_to(:password_digest) }
it { should respond_to(:password) }
it { should respond_to(:password_confirmation) }
it { should be_valid }
.
.
.
describe "when password is not present" do
before do
@user = User.new(name: "Example User", email: "[email protected]",
password: " ", password_confirmation: " ")
end
it { should_not be_valid }
end
describe "when password doesn't match confirmation" do
before { @user.password_confirmation = "mismatch" }
it { should_not be_valid }
end
end
Мы можем получить прохождение тестов из Листинга 6.25 используя лишь одну строку кода - как это показано в Листинге 6.26.
app/models/user.rb class User < ActiveRecord::Base
.
.
.
has_secure_password
end
Примечательно что одна линия
has_secure_password
приводит к прохождению всех текущих тестов пароля. На самом деле она делает гораздо больше, даже слишком много, мешая будущим тестам краснеть перед позеленением, так что прежде чем двигаться дальше я рекомендую закоментировать эту строку (Листинг 6.27).
has_secure_password для соблюдения цикла TDD. app/models/user.rb class User < ActiveRecord::Base
.
.
.
# has_secure_password
end
6.3.3 Аутентификация пользователя
Последняя часть механики наших паролей это метод для получения пользователей по их email и паролям. Эта задача естественным образом разбивается на две части: первая из них это поиск пользователя по адресу электронной почты; вторая это аутентификация пользователя с данным паролем. Все тесты (кроме последнего) в этом разделе связаны с has_secure_password, так что в процессе реализации вы должны иметь возможность раскомментировать закоментированную строку из Листинга 6.27 для того чтобы дать тестам возможность пройти.
Первый шаг прост; как мы видели в Разделе 6.1.4, мы можем найти пользователя с данным адресом электронной почты с помощью метода find_by:
user = User.find_by(email: email)
Второй шаг заключается в применении метода authenticate для проверки того что у пользователя есть данный пароль. В Главе 8, мы будем получать текущего (вошедшего) пользователя используя код вроде этого:
current_user = user.authenticate(password)
Если данный пароль совпадает с паролем пользователя, он должен вернуть пользователя; в противном случае он должен вернуть false.
Как обычно, мы можем выразить требования для authenticate используя RSpec. Получившиеся в результате тесты являются немного более продвинутыми чем те что мы видели до этого, так что давайте разобьем их на части; если вы новичок в RSpec, вам возможно понадобится прочитать этот раздел несколько раз. Мы начнем с того, что объект User должен отвечать на authenticate:
it { should respond_to(:authenticate) }
Затем мы покрываем два случая - совпадение и несовпадения пароля:
describe "return value of authenticate method" do
before { @user.save }
let(:found_user) { User.find_by(email: @user.email) }
describe "with valid password" do
it { should eq found_user.authenticate(@user.password) }
end
describe "with invalid password" do
let(:user_for_invalid_password) { found_user.authenticate("invalid") }
it { should_not eq user_for_invalid_password }
specify { expect(user_for_invalid_password).to be_false }
end
end
Блок before сохраняет пользователя в базе данных, так что он может быть получен с помощью find_by, чего мы достигаем используя let method:
let(:found_user) { User.find_by(email: @user.email) }
Мы уже использовали let в нескольких упражнениях, это первый случай когда мы его видим в основном тексте учебника. Блок 6.3 рассказывает о let более подробно.
Два блока describe покрывают случаи когда @user и found_user должны быть одинаковыми (совпадение пароля) и разными (несовпадение пароля); они используют “равенство” eq для проверки эквивалентности объектов (который в свою очередь использует ==, как мы видели в Разделе 4.3.1). Обратите внимание что тесты в
describe "with invalid password" do
let(:user_for_invalid_password) { found_user.authenticate("invalid") }
it { should_not eq user_for_invalid_password }
specify { expect(user_for_invalid_password).to be_false }
end
используют let второй раз, а также используют метод specify. Это просто синоним для it, который может быть использован когда it звучит ненатурально.
Наконец, в качестве дополнительной меры предосторожности, мы протестируем на наличие валидации длины паролей, установив длину паролей не меньшей чем шесть знаков:
describe "with a password that's too short" do
before { @user.password = @user.password_confirmation = "a" * 5 }
it { should be_invalid }
end
Собрав вместе все тесты мы получаем Листинг 6.28.
authenticate. spec/models/user_spec.rbrequire 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "[email protected]",
password: "foobar", password_confirmation: "foobar")
end
subject { @user }
.
.
.
it { should respond_to(:authenticate) }
.
.
.
describe "with a password that's too short" do
before { @user.password = @user.password_confirmation = "a" * 5 }
it { should be_invalid }
end
describe "return value of authenticate method" do
before { @user.save }
let(:found_user) { User.find_by(email: @user.email) }
describe "with valid password" do
it { should eq found_user.authenticate(@user.password) }
end
describe "with invalid password" do
let(:user_for_invalid_password) { found_user.authenticate("invalid") }
it { should_not eq user_for_invalid_password }
specify { expect(user_for_invalid_password).to be_false }
end
end
end
Как было отмечено в Блоке 6.3, let мемоизирует свое значение, так что первый вложенный describe блок в Листинге 6.28 вызывает let для получения пользователя из базы данных с помощью find_by, но второй describe блок уже не обращается к базе данных.
6.3.4 У пользователя есть безопасный пароль
В предыдущей версии Rails, добавление безопасного пароля было сложным и долгим, как это можно увидеть в Rails 3.0 версии Rails Tutorial18, где описано создание аутентификационной системы с нуля. Но понимание веб-разработчиками того как лучше всего аутентифицировать пользователей созрело настолько, что она (аутентификация) теперь поставляется в комплекте с последней версией Rails. В результате чего мы закончим реализацию безопасных паролей (и получим зеленый набор тестов) используя лишь несколько строк кода.
Во-первых, нам нужна валидация длины для пароля которая использует ключ :minimum по аналогии с ключом :maximum из Листинга 6.12:
validates :password, length: { minimum: 6 }
(Валидации наличия и подтверждения автоматически добавляются has_secure_password.)
Во-вторых, нам нужно добавить к атрибутам password и password_confirmation требование наличия пароля, требование их совпадения и добавить authenticate метод для сравнения зашифрованного пароля с password_digest для аутентификации пользователей. Это единственный непростой шаг и в последней версии Rails все эти фичи бесплатно поставляются в одном методе - has_secure_password:
has_secure_password
Пока столбец password_digest присутствует в базе данных, добавление одного лишь этого метода к нашей модели дает нам безопасный способ для создания и аутентификации новых пользователей.
(Если вы хотите увидеть как реализован has_secure_password, я советую взглянуть на хорошо документированый и вполне читабельный исходный код secure_password.rb. Этот код включает строки
validates_confirmation_of :password,
if: lambda { |m| m.password.present? }
которые (как описано в Rails API) автомагически создают атрибут password_confirmation. Он также включает валидацию для password_digest атрибута.
Совместно с валидацией наличия из Листинга 6.26, вышеприведенные элементы приводят к модели User показаной в Листинге 6.29, который завершает реализацию безопасных паролей.
app/models/user.rbclass User < ActiveRecord::Base
before_save { self.email = email.downcase }
validates :name, presence: true, length: { maximum: 50 }
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i
validates :email, presence: true,
format: { with: VALID_EMAIL_REGEX },
uniqueness: { case_sensitive: false }
has_secure_password
validates :password, length: { minimum: 6 }
end
Теперь необходимо убедиться что набор тестов проходит:
$ bundle exec rspec spec/
Примечание: Если вы получили deprecation warning вроде
[deprecated] I18n.enforce_available_locales will default to true in the future
вы можете попробовать избавиться от него отредактировав config/application.rb следующим образом:
require File.expand_path('../boot', __FILE__)
.
.
.
module SampleApp
class Application < Rails::Application
.
.
.
I18n.enforce_available_locales = true
.
.
.
end
end
6.3.5 Создание пользователя
Теперь, когда базовая модель User завершена, мы создадим пользователя в базе данных в качестве подготовки к созданию страницы показывающей информацию о пользователе в Разделе 7.1. Это также даст нам шанс сделать работу, проделанную в предыдущих разделах, более ощутимой; одни лишь проходяшие тесты могут показаться разочаровывающим результатом - гораздо приятнее увидеть настоящую запись пользователя в базе данных.
Поскольку мы пока не можем зарегистрироваться через веб-интерфейс — это является целью Главы 7 — мы будем использовать Rails консоль для создания нового пользователя вручную. В отличие от Раздела 6.1.3, в этом разделе мы не должны работать в песочнице, поскольку в этот раз нашей целью является сохранение записи в базе данных:
$ rails console
>> User.create(name: "Michael Hartl", email: "[email protected]",
?> password: "foobar", password_confirmation: "foobar")
=> #<User id: 1, name: "Michael Hartl", email: "[email protected]",
created_at: "2013-03-11 20:45:19", updated_at: "2013-03-11 20:45:19",
password_digest: "$2a$10$kn4cQDJTzV76ZgDxOWk6Je9A0Ttn5sKNaGTEmT0jU7.n...">
Для того чтобы проверить что это работает, давайте взглянем на строку в девелопмент базе данных (db/development.sqlite3) с помощью SQLite Database Browser (Рис. 6.6). Обратите внимание, что столбцы соответствуют атрибутам модели данных, определенной на Рис. 6.5.
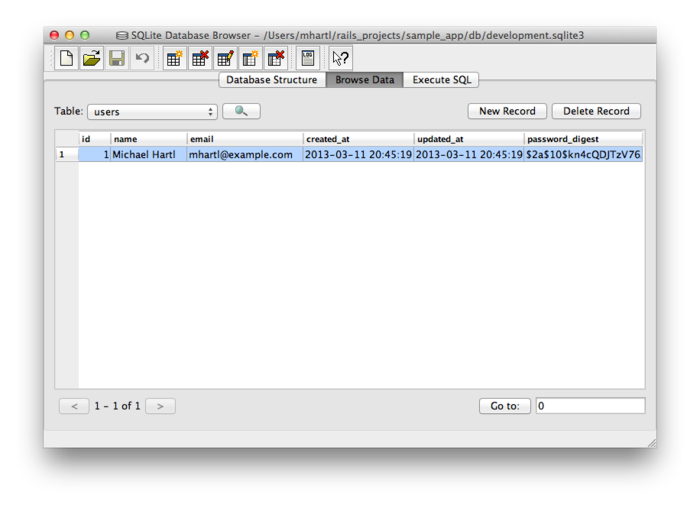
db/development.sqlite3. (полный размер){kind=link}
Вернувшись в консоль, мы можем увидеть эффект has_secure_password из Листинга 6.29 посмотрев на атрибут password_digest:
>> user = User.find_by(email: "[email protected]")
>> user.password_digest
=> "$2a$10$kn4cQDJTzV76ZgDxOWk6Je9A0Ttn5sKNaGTEmT0jU7.ncBJ/60gHq"
Это зашифрованная версия пароля ("foobar") которая была использована для инициализации объекта user. Мы также можем проверить что команда authenticate работает, использовав вначале невалидный, а затем валидный пароли:
>> user.authenticate("invalid")
=> false
>> user.authenticate("foobar")
=> #<User id: 1, name: "Michael Hartl", email: "[email protected]",
created_at: "2013-03-11 20:45:19", updated_at: "2013-03-11 20:45:19",
password_digest: "$2a$10$kn4cQDJTzV76ZgDxOWk6Je9A0Ttn5sKNaGTEmT0jU7.n...">
Как и требовалось тестами в Листинге 6.28, authenticate возвращает false если пароль невалиден и самого пользователя в противном случае.
6.4 Заключение
Начав с нуля, в этой главе мы создали рабочую модель User с name, email и различными "парольными" атрибутами, вместе с валидациями обеспечивающими несколько важных ограничений на их значения. Кроме того, мы можем безопасно аутентифицировать пользователей с помощью пароля. В предыдущих версиях Rails такой подвиг потребовал бы в два раза большего количества кода, но благодаря компактному методу validates и has_secure_password, мы смогли построить рабочую модель User используя меньше дюжины строк исходного кода.
В следующей (седьмой) главе мы сделаем рабочую форму регистрации для создания новых пользователей, вместе со страницей для отображения информации о каждом пользователе. В Главе 8 мы будем использовать механизм аутентификации из Раздела 6.3 для того чтобы дать пользователям возможность входить на сайт.
Если вы используете Git, было бы неплохо закоммитить внесенные изменения, если вы этого еще не сделали:
$ git add .
$ git commit -m "Make a basic User model (including secure passwords)"
Затем опять объединить их с мастер веткой:
$ git checkout master
$ git merge modeling-users
6.5 Упражнения
- Добавьте тесты для кода отвечающего за перевод email в нижний регистр из Листинга 6.20, как это показано в Листинге 6.30. Этот тест использует метод
reloadдля перезагрузки значения из базы данных и методeqдля тестирования на равенство. Закомменировав строкуbefore_saveубедитесь что тесты из Листинга 6.30 тестируют правильные вещи. - Запустив набор тестов убедитесь что коллбэк
before_saveможет быть написан способом показанным в Листинге 6.31. - Как было отмечено в Разделе 6.2.4, регулярное выражение для email в Листинге 6.14 позволяет невалидные адреса электронной почты с последовательно расположенными точками, т.e., адреса вида “[email protected]”. Добавьте этот адрес в список невалидных адресов в Листинге 6.13 для того чтобы получить провальный тест, а затем с помощью усложненного регулярного выражения показанного в Листинге 6.32 добейтесь прохождения этого теста.
- Прочитайте Rails API введение для
ActiveRecord::Baseдля того чтобы получить представление о ее возможностях. - Изучите Rails API введение для метода
validatesдля того чтобы больше узнать о его возможностях и опциях. - Поиграйте пару часов с Rubular.
spec/models/user_spec.rb require 'spec_helper'
describe User do
.
.
.
describe "email address with mixed case" do
let(:mixed_case_email) { "[email protected]" }
it "should be saved as all lower-case" do
@user.email = mixed_case_email
@user.save
expect(@user.reload.email).to eq mixed_case_email.downcase
end
end
.
.
.
end
before_save. app/models/user.rb class User < ActiveRecord::Base
has_secure_password
before_save { email.downcase! }
.
.
.
end
app/models/user.rb class User < ActiveRecord::Base
.
.
.
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-]+(\.[a-z]+)*\.[a-z]+\z/i
validates :email, presence: true, format: { with: VALID_EMAIL_REGEX },
uniqueness: { case_sensitive: false }
.
.
.
end
- Имя происходит от “паттерна active record”, определенного и названного в Patterns of Enterprise Application Architecture Мартина Фаулера. ↑
- Произносится “ess-cue-ell”, хотя альтернативное произношение “sequel” также возможно. ↑
- Используя адреса электронной почты в качестве имени пользователя мы открываем теоретическую возможность связи с нашими пользователями в будущем. ↑
- Не волнуйтесь о том, как объект
tделает это; красота уровней абстракции (the beauty of abstraction layers) состоит в том, что мы не должны этого знать. Мы можем просто доверить объектуtделать его работу. ↑ - Официально произносится как “ess-cue-ell-ite”, тем не менее, вариант произношения “sequel-ite” также возможен. ↑
- На случай, если
"2013-03-11 00:57:46"вызвало ваше любопытство - я не пишу это после полуночи; временнЫе метки записаны во Всемирном координированном времени (UTC), которое для многих практических целей является аналогом Среднего времени по Гринвичу. Из NIST Time and Frequency FAQ: Q: Почему UTC используется в качестве акронима к Coordinated Universal Time вместо CUT? A: В 1970 система Coordinated Universal Time была разработана международной консультативной группой технических экспертов в рамках International Telecommunication Union (ITU). ITU чувствовал, что было лучше определить единственное сокращение для использования на всех языках, чтобы минимизировать беспорядок. Так как единогласное соглашение не могло быть достигнуто при использовании английского порядка слов, CUT, или французского порядка слов, TUC, акроним, UTC был выбран в качестве компромисса. ↑ - Значение
user.updated_atговорит вам о том что временнАя метка была в UTC. ↑ - Исключения и обработка исключений - несколько более продвинутые предметы Ruby и мы не сильно будем нуждаться в них в этой книге. Они важны, тем не менее, и я предлагаю узнать о них используя одну из книг, рекомендованных в Разделе 1.1.1. ↑
- Это подразумевает что вы используете SQLite локально. Этих файлов не будет если вы вместо SQLite используете Postgres как это рекомендовалось в одном из упражнений Главы 3. ↑
- Я опускаю выводы консольных команд когда они не особенно поучительны, например, результат
User.new. ↑ - Обратите внимание, что в Таблице 6.1, “буква” на самом деле означает “строчную букву”, но
iв конце regex обеспечивает нечувствительность к регистру. ↑ - Если вы считаете это столь же полезным, как я, призываю вас внести пожертвование чтобы вознаградить разработчика Michael Lovitt за его замечательную работу над Rubular. ↑
- Знаете ли вы, что
"Michael Hartl"@example.com, с кавычками и пробелом в середине - является допустимым адресом электронной почты согласно стандарту? ↑ - Как было вкратце отмечено во введении в этот раздел, есть отдельная тестовая база данных,
db/test.sqlite3для этой цели. ↑ - Технически, только доменная часть email адресов является нечувствительной к регистру: [email protected] на самом деле отличается от [email protected]. На практике, однако, полагаться на этот факт - плохая идея; как было отмечено в about.com, “Поскольку регистрозависимость email адресов может создать много неурядиц, пробем с совместимостью и головных болей, было бы глупым требовать чтобы email адреса набирались исключительно в правильном регистре. Врядли какой-либо из email сервисов или ISP обращает внимание на регистр email адресов, возвращая сообщения в которых email получателя был набран неправильно (в верхнем регистре, например). ” Спасибо читателю Riley Moses за указание на этот факт. ↑
- Конечно, мы могли только отредактировать файл миграции для таблицы
usersв Листинге 6.2, но для этого потребовалось бы откатить, а затем вновь накатить миграцию базы данных. Rails Way заключается в использовании миграции каждый раз, когда мы обнаруживаем, что нам необходимо изменить модель данных. ↑ - Непосредственные эксперименты со SQLite на моей системе и с PostgreSQL на Heroku показали что этот шаг фактически необходим. ↑
- https://railstutorial.ru/book?version=3.0 ↑